Compiler From Scratch: Phase 1 - Tokenizer Generator 022: Resolving DFA state ambiguity
Streamed on 2024-12-13 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
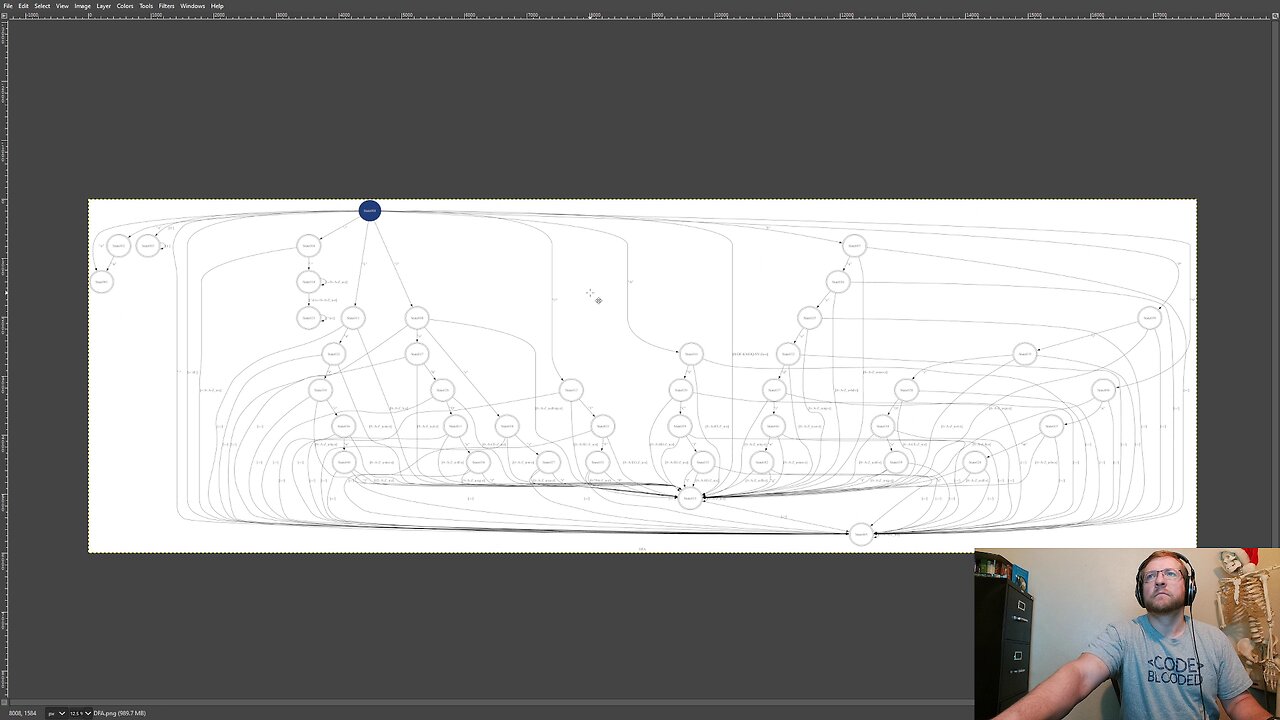
Last week we got stuck by the fact that DFAs can have overlapping transitions. In these cases the first test always wins and there is no way to jump off an invalid track onto another valid track once it starts down a track. So we fixed that today.
The trick is to think of each transition as a set of characters; a set in the mathematical sense. When processing the transitions we look for overlapping sets. If they overlap we compute:
1) Which characters are only in the first set
2) Which characters are only in the second set
3) Which characters are in both sets, and treat that as a new transition that follows the lowest rule number (rule order precedence).
Then add each of these three onto the unprocessed list for further checking. Once a transition makes it all the way through the unprocessed list without overlapping any other sets, this transition if put on the processed list. This process also has the added benefit of making the order we check the transitions in not matter at all. We can shuffle the transitions into any order, and since they don't overlap any more, they will all be checked eventually and not get cut off by an overlapping rule. Now the DFA looks much messier, but it is finally correct.
With that change done the testing of VVProject tokenizer proceeded. It didn't take much fiddling to get it the way we want. We had already done most of the plumbing into VVProject last week and with a bit of tweaking it was working just fine there as well.
I started down the road of making a tokenizer for the VVTokenizerDefinition, but got sidetracked thinking about multiple-encodings support in that tokenizer. I started down a dark road trying to make that work, but where VVProject calls VVTokenizerDefinition was where I found the problem: for the "Multi" encoding to work it would have to know the encoding when we generate the tokenizer itself. We can't switch that encoding behavior at tokenizer runtime with this system, only at tokenizer generation time. And the biggest problems is the REGEX tokenizing rule. That will have to support anything at tokenization time. I have a plan, but ran out of time by the time I had thought it through. We'll have to remove some of the work we did today, but that will have to wait for next week.
-
 3:35:57
3:35:57
SlantRock
3 hours agoBATTLEFIELD REDSEC/ MAYBE ARC RAIDERS AFTER
600 -
 LIVE
LIVE
Astral Doge Plays!
1 hour agoHyrule Warriors: Age of Imprisonment ~LIVE!~ Ganondorf Is a Jerk
74 watching -
 1:25:13
1:25:13
Kim Iversen
3 hours agoMKUltra Victims Are SUING — The CIA's Darkest Secret EXPOSED
88.9K44 -
 LIVE
LIVE
GritsGG
5 hours ago#1 Most Warzone Wins 4015+!
83 watching -
 16:30
16:30
Stephen Gardner
3 hours ago🚨OVAL OFFICE EXPOSES TRUMP TAKEOVER – FILIBUSTER NUKED!
17.5K24 -
 LIVE
LIVE
The Rabble Wrangler
16 hours agoThe Best in the West Dominates Battlefield
33 watching -
 LIVE
LIVE
cosmicvandenim
3 hours agoCOSMIC VAN DENIM
55 watching -
 1:34:03
1:34:03
Redacted News
4 hours agoBREAKING! CIA FURIOUS & EMERGENCY WHITE HOUSE MEETING - ISRAELI SPY CAUGHT MEETING WITH AMB HUCKABEE
128K115 -
 1:22:06
1:22:06
vivafrei
5 hours agoCFIA Goes After a REFUGE? Charlie Kirk Missing Evidence "Uncovered"? Democrats are Epostein Simps!
130K64 -
 1:44:33
1:44:33
The Quartering
6 hours agoTrump Calls For Hangings, McDonalds SNAP Controversy, The Demonic Relationship In Wicked & More
159K70