ActInf GuestStream 115.1 ~ Energy-Based Transformers and the Future of Scaling
"Energy-Based Transformers are Scalable Learners and Thinkers"
Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, Tariq Iqbal
https://arxiv.org/abs/2507.02092
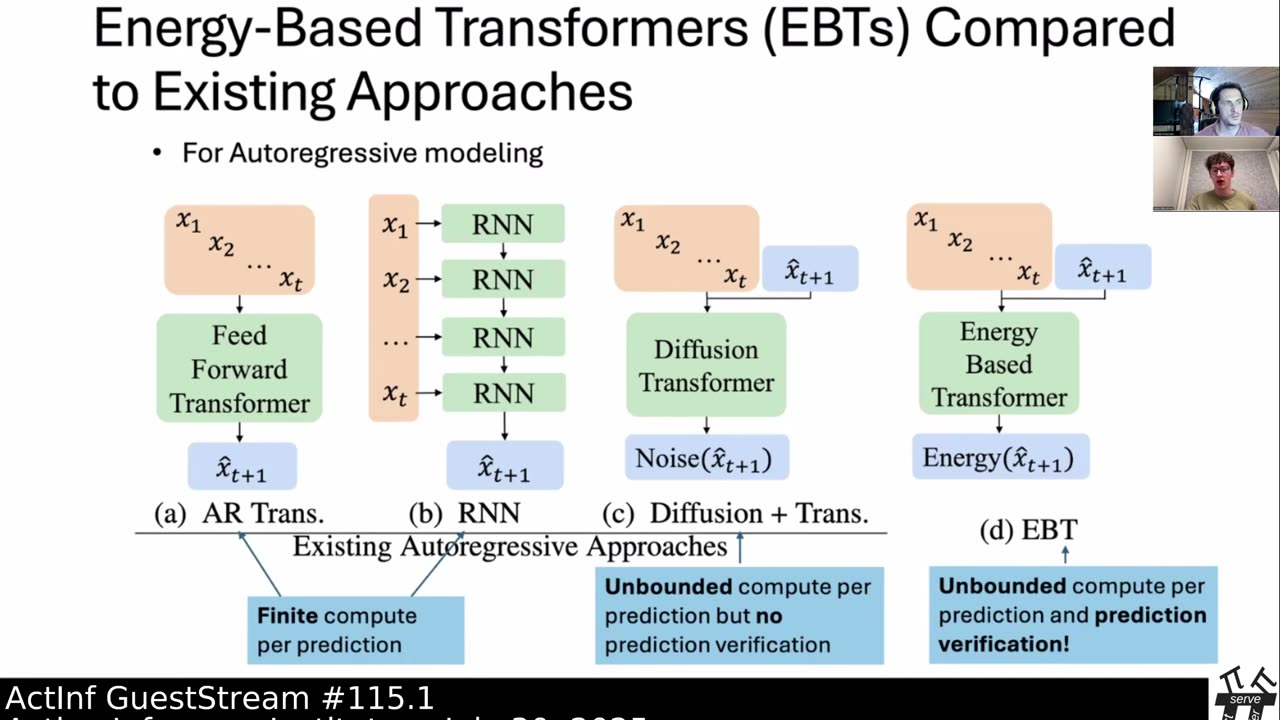
Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
Cite as: arXiv:2507.02092 [cs.LG]
(or arXiv:2507.02092v1 [cs.LG] for this version)
https://doi.org/10.48550/arXiv.2507.02092
Active Inference Institute information:
Website: https://www.activeinference.institute/
Activities: https://activities.activeinference.institute/
Discord: https://discord.activeinference.institute/
Donate: http://donate.activeinference.institute/
YouTube: https://www.youtube.com/c/ActiveInference/
X: https://x.com/InferenceActive
Active Inference Livestreams: https://video.activeinference.institute/
-
 2:16:55
2:16:55
Active Inference Institute
1 month ago5th Applied Active Inference Symposium (Part 3, Nov 14, 2025) ~ LIVE
121 -
 LIVE
LIVE
Barry Cunningham
1 hour agoLIVE BREAKING NEWS: President Trump Addresses The Nation! And More News!
2,421 watching -
 LIVE
LIVE
The White House
1 hour agoPresident Trump Delivers an Address to the Nation
2,961 watching -
 LIVE
LIVE
Laura Loomer
1 hour agoEP162: LIVE: President Trump Addresses The Nation
2,210 watching -
 LIVE
LIVE
Drew Hernandez
18 hours agoTRUMP ADDRESSES THE NATION & BONGINO ANNOUNCES FBI DEPARTURE?
663 watching -
 LIVE
LIVE
Badlands Media
12 hours agoBadlands Media Special Coverage - MY FELLOW AMERICANS the Alpha Warrior Show & Redpill Project
3,158 watching -
 22:54
22:54
Jasmin Laine
7 hours agoMedia MELTS DOWN as Poilievre Surges—Ottawa Loses Control of the Narrative
7158 -
 59:50
59:50
BonginoReport
4 hours agoDan Bongino Is Leaving The FBI - Nightly Scroll w/ Hayley Caronia (Ep.199)
229K177 -
 1:14:51
1:14:51
Kim Iversen
5 hours agoSTILL SHADY: Candace Meets With Erika — She Was Right
136K173 -
 1:04:57
1:04:57
Candace Owens
5 hours agoBREAKING NEWS! We Received Photos Of Charlie's Car After The Assassination. | Candace Ep 281
119K329